Introduction to machine learning
Democratization of machine learning will create amazing products and services for us. Let us understand what it is.
Machine learning has been a hot topic. But what is machine learning?
Let me explain machine learning, with an anecdote shared by my favorite entrepreneur-philosopher Derek Sivers.
Tim Ferriss (author of popular 4-hour workweek) interviewed Derek Sivers for a podcast. During the course of the podcast, Tim asked how Sivers scaled CD Baby, a company Sivers started and sold for 22 million dollars. Typical of Sivers, he replied with an anecdote.
I had 20 employees, but still almost everything went through me. And it made my day kind of miserable, because I’m a real introverted kind of focused person, I love to just sit down for 12 hours and do one thing without distraction.
So then next time somebody asked me a question I gathered everybody around. I said "okay, stop working everybody, gather around, Tracy asked what we do if somebody wants a refund. Here is not only what we do, but here is why, here is my philosophy: whenever somebody wants a refund we should always give it to them…". And I would just explain, not just the what to do, but the why. It was constantly communicating the philosophy.
What Derek did was a typical case of knowledge transfer from one brain to another brain, which is the basis of machine learning. In fact, later in the podcast, he says this:
there’s almost nothing that really has to be you, you can almost get kind of AI and figure out how your brain works, how your decision-making process works, and just teach it to other people, so that other people can do it.
What Derek describes in this paragraph is machine learning. As Arthur Samuel says, machine learning is "giving computers the ability to learn without being explicitly programmed."
# Programming so far
Until now, we have explicitly programmed computers to form decision. For this, the programmers should know the input parameters and the logic to make that decision when they write the software application.
Take the case of refunds. No refund ever or always refund, is a simple logic. Pseudo-code to handle never refund would look like this:
if (customer_request == 'refund') {
answer = 'NO'
}
A decision-tree is also an easy-to-handle logic for a computer. A decision-tree could look like this in pseudo-code:
if (customer_request == 'refund'){
if (bill < 100) {
answer = 'YES'
} else if (repeat_customer) {
answer = 'YES'
} else {
Answer = 'No'
}
}
Most of the current software applications follow one of these two kinds of logic — either a simple yes or no logic or a series of multi-choice decision-tree.
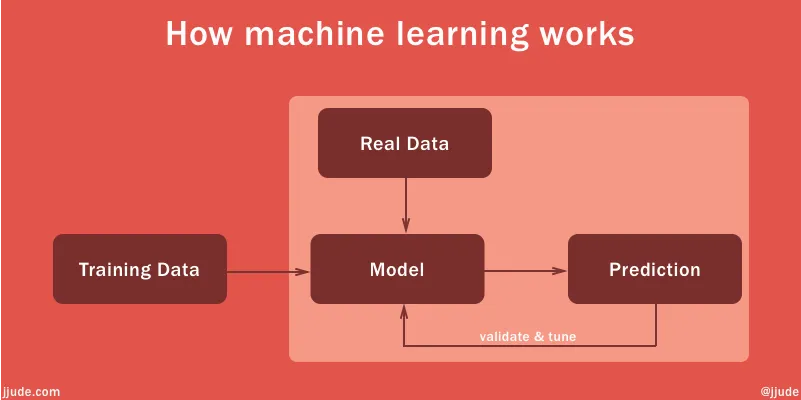
# How machine learning works
Like in programming, customer service employees are usually given a decision tree to answer clients. Derek being Derek, he didn't hand such a simple logic to his employees. He mentions:
It was constantly communicating the philosophy
This is not the usual "input + logic = decision" flow. Derek reverses the flow. He says, here is the decision and this is why I made it. If you sit with him and analyze all his decisions like this, you can figure out his decision-making. Then you can decide if he would give a refund, if he would move to New Zealand, if he would read a particular article, if he would date a particular person, and so on.
Machine learning works in a similar fashion. You pick up training dataset, which has the data and the result (decisions in the example of Derek). Use this to formulate a model. Then you feed real-data into this model to predict a result. As you validate the predicted result, the model learns which in-turn improves its result.
Sites like Amazon use similar technique. In fact, they go a step further. Since they can't sit next to you to analyze the decision, they guess why you bought a book (or any item). When you buy your first book, the system records it with as much information as it has — a Kindle book with 25% discount on consulting written by Alan Weiss, an American author and so on. As you continue to buy books, Amazon system deducts a pattern. May be you buy books on discount, may be you buy kindle books (i.e., medium), may be you buy books on consulting (i.e., genre), may be you buy books by Alan Weiss (i.e., author) and so on. If you buy books on consulting, it will start recommending other books on consulting. If you buy the recommended books, the system confirms its model of you; if you don't buy the recommended books, then it alters the model.
Recommendation engine is only one application of machine learning. There are other uses of machine learning. Facebook uses machine learning to identify people in photos. Financial industry uses machine learning to identify credit-card frauds. Companies monitor social-media sites for positive and negative comments using machine learning.
# Categories of machine learning algorithms
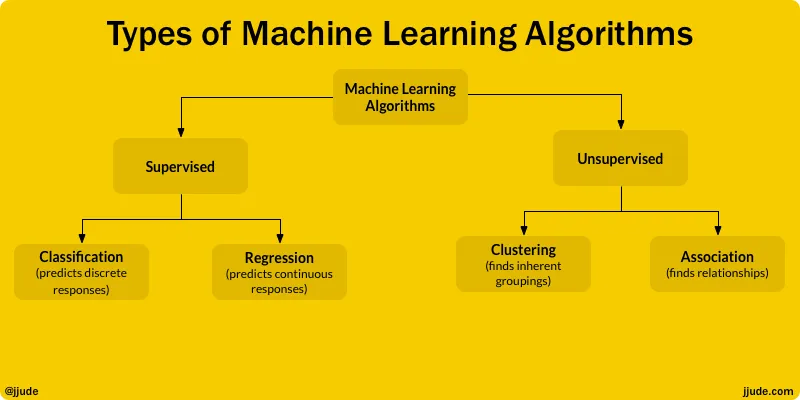
There are two broad categories of machine learning algorithms. John W. Foreman explains these two categories in his book Data Smart.
If I know I want to divide customers into two groups—say, "likely to purchase" and "not likely to purchase"—and I provide the computer with historical examples of such customers and tell it to assign all new leads to one of these two groups, that's supervised.
In exploratory data mining, you don't know ahead of time what you're looking for. You're an explorer. Like Dora. You may be able to articulate when two customers look the same and when they look different, but you don't know the best way to segment your customer base. So when you ask a computer to segment your customers for you, that's called unsupervised machine learning, because you're not "supervising"—telling the computer how to do its job.
Let me explain the difference with a real-life example. I take lot of photos. I take as many as 400 photos in a weekend trip. It takes a lot of time to organize — deleting unwanted photos and tagging photos.
Now-a-days I use Apple Photos app to organize photos. I identify persons and tag them in as many photos as I can. Then the app goes through rest of the photos and automatically tags people in them. As I verify these automatic tagging, the tagging gets better in successive photos. This is supervised learning.
I would like another feature from photos app. If the app can scan the photos and automatically tag photos with certain features (balloons, cars, landscape, out-of-focus and so on) that will help me tremendously. If the app had this feature, it would be unsupervised learning.
These machine learning algorithms can be further divided.
Supervised machine learning algorithms can be divided into classification and regression algorithms.
Classification algorithms "classifies" data into discrete responses. For example, anti-spam algorithms classifies emails into spam and ham (not-spam). If an algorithm classifies set of objects into "red", "orange", "pink", and so on, then it is classification algorithm too.
Regression algorithms "predict" a continuous response. They are used in primarily for forecasting. Forecasting algorithms analyze past data and predict values in the future. Temperature forecasting and sales forecasting are two usages of regression algorithm.
Like supervised algorithms, Unsupervised algorithms can be classified into clustering and association algorithms.
Clustering algorithms find inherent grouping in a large dataset. Some examples are grouping customers based on buying behaviors or grouping houses based on house-type, value, and geography.
Association algorithms find relationships between elements in a large dataset. Association algorithms can find out that customers who buy beers also buy diapers.
# Ready for masses
Machine learning is no more sophisticated science exclusive for few elites. Major cloud providers like Amazon, Google, and Azure already provide machine learning algorithms as a service. Apache is offering an open source server for machine learning called PredictionIO. Google has introduced Tensorflow, an open source machine learning framework, which you can use in web, desktop, and mobile applications.
Such democratization of machine learning will create amazing products and services for us.
# Summary
- Machine learning is the science of getting computers to act without being explicitly programmed.
- Supervised machine learning builds a model that makes predictions based on evidence
- Classification techniques predict discrete responses
- Regression techniques predict continuous responses
- Unsupervised learning finds hidden patterns or intrinsic structures in data.
- Clustering finds inherent groupings
- Association finds relationships in large data sets
Under: #coach , #tech